XMLBluePrintでXMLからXSDを生成する
これまで使ってきた法令のXMLファイルからXSDを生成してみます。
その後、WebでダウンロードできるXSDファイルと比較して、どれぐらい差があるかを見てみます。
- まずはこれまで通り、法令のXMLファイルをXMLBluePrintで開きます。
XMLBluePrintで開く - 「スキーマ」メニューから「サンプルXMLからXSDを生成」を選択します。

- いくつかの同形式のXMLファイルを指定することで、生成の精度が上がるようですが、まずは、1つのファイルだけでやってみます。

- 「OK」をクリックすると、一瞬で生成されます。
生成されたXSDファイルは、元のXMLファイルのある場所に、拡張子を .xsd に変えて、同じ名前で保存されます。

生成されたXSD - さて、XSDを比較してみます。今生成されたXSDはタブで切り替えることができますが、2つのXSDファイル、今回は、Webからダウンロードした公式のXSDとXMLBluePrintで生成したXSDを比較したいのですが、タブではうまくいきません。
実はXMLBluePrintは同じマシンで複数起動できます。なので、もう一度、「スタート」メニューから「XMLBluePrint」を選択するともう1つのウィンドウが開きます。
この中で、ダウンロードしてきたXSDファイルを開いて、横に並べます。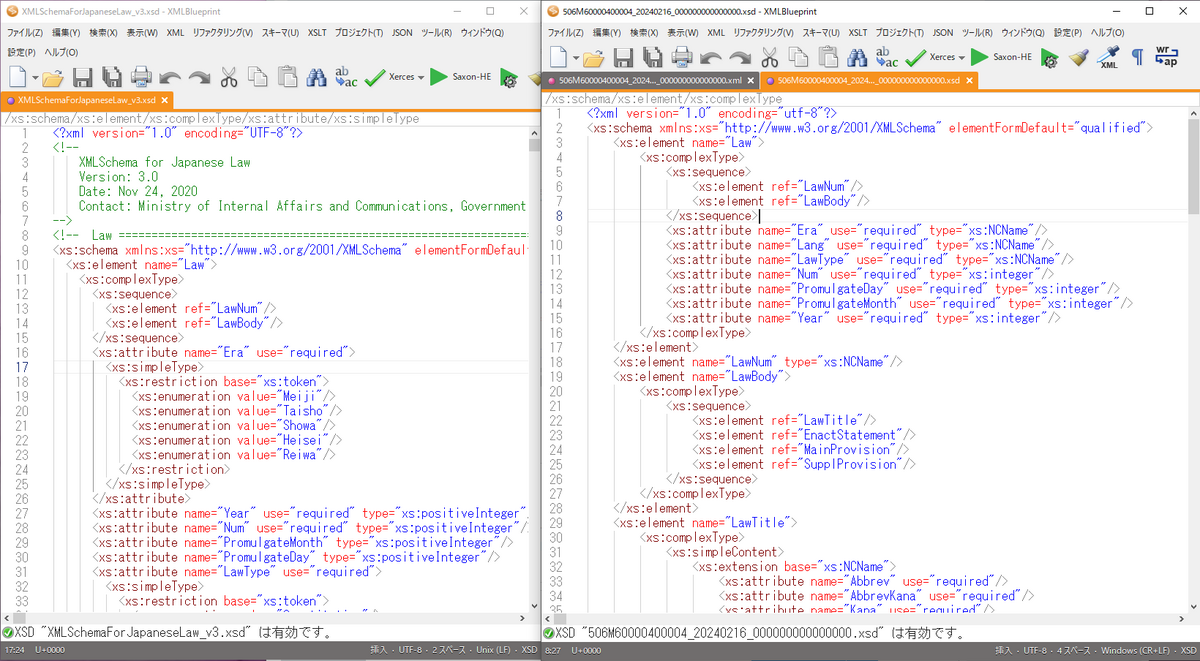
XSDファイルを見比べる - 冒頭の次の部分を見てみると、一見違いますが、XMLファイル1つだけでこれが「enumeration」(列挙型)であることはわからないので、仕方がないと思います。
Webページの公式XSD
XMLBluePrintで生成されたXSD
<xs:attribute name="Era" use="required">
<xs:simpleType>
<xs:restriction base="xs:token">
<xs:enumeration value="Meiji"/>
<xs:enumeration value="Taisho"/>
<xs:enumeration value="Showa"/>
<xs:enumeration value="Heisei"/>
<xs:enumeration value="Reiwa"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
<xs:attribute name="Era" use="required" type="xs:NCName"/>
- これに続く部分はというと、わりとうまくいっていると思います。見やすくするために順番を入れ替えて、並べてます。
やはり、「enumeration」は1つでは、「他にどんな値があるか」がわからないので、だめです。このセクションでは、「LawType」と「Lang」です。
あと、オリジナルは「positiveInteger」ですが、生成されたものは「Integer」です。ファイルを見ただけでは、「絶対にすべて正の整数である」とは言い切れないでしょう。Webページの公式XSD
XMLBluePrintで生成されたXSD
<xs:attribute name="Year" use="required" type="xs:positiveInteger"/>
<xs:attribute name="Num" use="required" type="xs:positiveInteger"/>
<xs:attribute name="PromulgateMonth" type="xs:positiveInteger"/>
<xs:attribute name="PromulgateDay" type="xs:positiveInteger"/>
<xs:attribute name="LawType" use="required">
<xs:simpleType>
<xs:restriction base="xs:token">
<xs:enumeration value="Constitution"/>
<xs:enumeration value="Act"/>
<xs:enumeration value="CabinetOrder"/>
<xs:enumeration value="ImperialOrder"/>
<xs:enumeration value="MinisterialOrdinance"/>
<xs:enumeration value="Rule"/>
<xs:enumeration value="Misc"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
<xs:attribute name="Lang" use="required">
<xs:simpleType>
<xs:restriction base="xs:token">
<xs:enumeration value="ja"/>
<xs:enumeration value="en"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
<xs:attribute name="Year" use="required" type="xs:integer"/>
<xs:attribute name="Num" use="required" type="xs:integer"/>
<xs:attribute name="PromulgateDay" use="required" type="xs:integer"/>
<xs:attribute name="PromulgateMonth" use="required" type="xs:integer"/>
<xs:attribute name="LawType" use="required" type="xs:NCName"/>
<xs:attribute name="Lang" use="required" type="xs:NCName"/>
- まあ、全体としてはうまくいっているでしょう。
そこで、少なくとも「enumeration」がうまくできるかどうかを見るために、いくつかの年代の法令XMLを変換時に指定します。
- いちいち、中身を見て「平成」なのか「昭和」なのかを見るのは面倒なので、適当にいくつかピックアップしました。

- さて、これで生成するとどうでしょう。
やはり取れないです。
それはそうか。列挙されるリストが、どこまで長くなるかはわからないし、それ以外にも値が出てくるかもしれないし。<xs:attribute name="Era" use="required" type="xs:NCName"/>
-
アウトラインだと比べやすいかな、と思ったのですが、並びが違うのでまだわかりにくい。

ただ、わかったことは、公式なXSDでは、もっと多くの要素がXSDで定義されていて、おそらく、変換時に全XMLファイルを指定して、抽出したとしても完全なものは作れないということです。
まあ、XSDを見ようとする人は、XMLを知っていて、本来のルールに会うように、XSDを変更することができる人が多いと思うので、そこまでを(高価ではない)ソフトには求めていない、ということになるんでしょうね。